点云配准是许多计算领域的一项关键任务。以前的基于对应匹配的方法要求输入具有不同的几何结构,以根据逐点稀疏特征匹配来适应3D刚性变换。然而,变换的准确性在很大程度上依赖于提取的特征的质量,这些特征容易出现偏好性和噪声方面的错误。此外,它们不能利用所有重叠区域的几何知识。另一方面,以往的基于全局特征的配准方法可以利用整个点云进行配准,但是在聚合全局特征时忽略了非重叠点的负面影响。
本文提出了一种基于全局特征的局部-局部点云配准迭代网络OMNet。我们学习重叠模板来拒绝非重叠区域,这将部分到部分的配准转化为相同形状的配准。此外,以前使用的数据仅从每个对象的CAD模型中采样一次,从而产生源和参考的相同点云。我们提出了一种更实用的数据生成方式,即对CAD模型进行两次采样作为源和参考,避免了以前普遍存在的过拟合问题。实验结果表明,与传统方法和基于深度学习的方法相比,我们的方法取得了最好的性能。
简介
点云配准是一项广泛应用于增强现实,三维重建,和自动驾驶等计算领域的基本任务。它的目标是预测对齐两个点云的3D刚性变换,这两个点云可能会被偏好性遮挡和被噪声污染。

增强现实【1】
3D重建【2】

自动驾驶【3】
以往方法以及缺陷
基于对应点匹配的方法
大多数基于对应匹配的方法通过交替两个步骤来解决配准问题:(1)建立源和参考点云之间的对应关系;(2)计算对应关系之间的最小二乘刚性变换。
寻找对应点首先需要知道一个初始的旋转平移变换,这个旋转平移变换是由粗配准得到的,粗配准目前还是一个难题,常见的粗配准搜索策略有4PC等。在知道了初始的旋转平移变换的前提下,我们对source cloud使用这个初始的旋转平移变换,得到一个变换之后的点云,然后将这个变换后的点云和target cloud进行比较,如果这两个点云之间存在点对{x,y}且xy之间的距离小于人为设定的阈值,那么我们就将{x,y}看做对应点。这就建立了源和参考点云之间的对应关系。
求解最小二乘刚性变换就不需要多说了,本质上就是最小二乘法问题。也即找到最好的旋转平移变换使得我们认为的对应点可以对应上。
常见的基于对应点匹配的方法包括ICP以及其的后续变体。ICP的变体通过检测关键点或加权对应来提高性能。然而,由于第一步的非凸性,它们往往会收敛到局部最小值。为了解决这个问题,Go-ICP使用分支定界策略来搜索转换空间,但代价是速度慢得多。最近提出的对称ICP[22]通过设计目标函数来改进原有的ICP。与使用空间距离不同,PFH[25]和FPFH[24]设计了旋转不变的描述符,并从手工制作的特征中建立对应关系。为了避免RANSAC[8]和最近邻的计算,FGR[40]使用交替优化技术来加速迭代。
非凸问题常常会使梯度下降陷入局部最小值,如图:
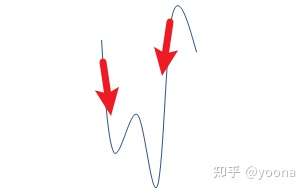
本质上,关于六自由度(旋转和平移)的3D点云配准问题是典型的非凸优化问题,其目标函数在六维可行域空间中具有多个波峰波谷,即优化求解过程中受初始变换矩阵影响,容易陷入局部最优解。
RANSAC算法通过反复随机选取数据来预测模型,以避免数据集中离群值的影响。
最近的基于DL的方法用CNN替换了手工制作的特征描述符。深度最近点(DCP)的方法可以确定学习特征的对应关系。DeepGMR集成了高斯混合模型(GMM)来学习姿势不变的点到GMM 的对应。然而,他们没有考虑到输入的偏差性,PRNet、RPMNet和IDAM被用来缓解这一问题,方法是使用带有Sinkhorn归一化的Gumbel-Softmax或卷积神经网络(CNN)来计算匹配矩阵。然而,这些方法要求输入具有独特的局部几何结构来提取可靠的稀疏3D特征点。
手工制作的特征描述符即人工标注,人工标注的意思即人为提取出数据中的特征,这些特征多数是人所感兴趣的,浅层的特征,然而人工提取的特征难免会有偏见以及想当然的成分,因此才提出了用CNN来提取更深层次的特征。
高斯混合模型即使用多维的高斯分布来描述多维特征
基于对应点匹配的方法的缺陷
ICP方法很容易就收敛到局部最小值,GO-ICP虽然避免了这一点,但是速度太慢了。
所有基于对应点匹配的方法都对源点云和目标点云的初始位置敏感,因此并不总是能得到很好的结果。
使用了深度学习提取特征的基于对应点匹配的方法要求源点云具有特定的几何结构以便更好地完成稀疏点的匹配,他们不能利用重叠点云的几何知识,这导致了只有有限的对应点可以完成匹配,或者导致很差的匹配。
变换仅仅由匹配的稀疏点以及其匹配的邻居计算,这导致点云中其他的点并没有参与到配准过程中。
基于全局的配准方法
与基于对应匹配的方法不同,基于全局特征的方法是从没有对应关系的两个输入的整个点云(包括重叠和非重叠区域)计算刚性变换。即,通过神经网络聚合全局特征来计算刚性变换。PointNetLK开创了这些方法,它将PointNet与Lucas&Kanade(LK)算法适配为递归神经网络。PCRNet通过将LK算法与回归网络交替使用来提高对噪声的稳健性。此外,FMR增加了译码分支,并优化了输入的全局特征距离。
基于全局的配准方法的缺陷
- 他们忽略了非重叠区域造成的负面影响
- 他们不能配准部分-部分的输入
部分到部分的配准方法
此方法将部分到部分点云的配准作为一个更现实的问题提出。特别是,PRNet将DCP扩展为迭代流水线,并通过检测关键点来解决输入的偏差性问题。此外,使用可学习的Gumble-Softmax来控制匹配矩阵的光滑性。RPMNet还利用Sinkhorn归一化来鼓励匹配矩阵的双射。但此方法仍只能用于稀疏点的匹配。
OMNet
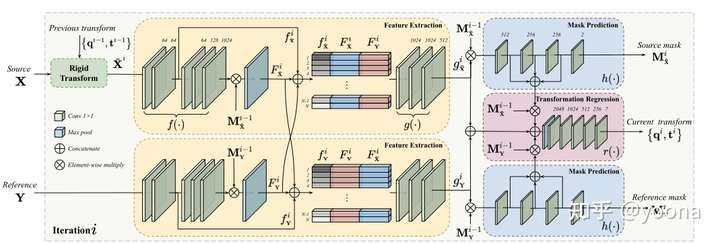
整个流水线如下图所示,文中是拆解成四部分,我根据个人理解拆解成5部分,主要是把特征提取这一步分成了两步:
- 输入:输入源点云X 和参考点云Y,并且点云X 完成上一轮的刚性变换
- 各自特征提取:点云X,Y都需要通过MLP进行特征提取,先经过上一轮的掩码将关注点转移到重叠区域的点之后,经过最大池化得到两个点云的全局特征。
- 融合特征提取:将X的逐点特征和X的全局特征和Y的全局特征相连,再次MLP抽取混合特征
- 新的掩码预测:将旧的掩码和融合特征经过预测函数(待会说)之后,得到新的掩码
- 刚性变换预测:将旧的掩码和掩码预测函数过程中得到的特征和之前的混合特征来计算刚性变换。
输入
输入点云X,并做出标准刚性变换得到源的输入。输入点云Y,得到参考的输入。
各自特征提取
特征提取模块的目的是学习一个函数 f(·) ,该函数可以分别从源点云X和参考点云Y生成有特色的全局特征 FX 和 FY 。一个重要的要求是应该保持原始输入的方向和空间坐标,以便刚性变换可以根据这两个全局特征之间的差异进行估计。受PointNet的启发,在每次迭代中,输入˜Xi和Y的全局特征由下式给出
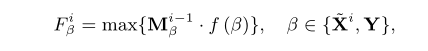
其中 f(·) 表示多层感知器网络,其被馈送 Xi 和 Y 以产生逐点特征 fXi 和 fYi 。 MXi−1 和 MYi−1 是˜ Xi 和 Y 的重叠遮罩,这两个遮罩是由上一步生成的, Xi 和 Y 的逐点特征通过最大池化操作 MAX{·} 聚集,该操作可以处理任意数量的无序点。
重叠遮罩的作用是提取出两个点云的重叠部分,可以让他们格式统一
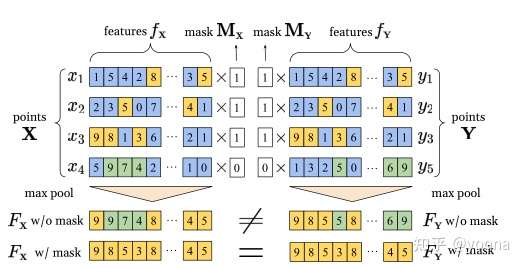
融合特征提取
这一步就是将X的逐点特征和X的全局特征和Y的全局特征相连,我个人的理解是这样就可以学习到XY的共同特征了,这样子就有利于后面重叠执照的预测,也就是把重叠的区域分割出来。
新的掩码预测
在局部到局部场景中,特别是包含噪声的场景中,输入点云X和Y之间存在非重叠区域。然而,它不仅对配准过程没有贡献,而且还干扰了全局特征提取。如上图所示。
在求解场景对齐的最近似矩阵时,传统的方法普遍采用RANSAC来寻找重叠点。遵循类似的思想,我们提出了一个掩码预测模块来自动分割重叠区域。参考PointNet,点分割只需要一个点云作为输入,并结合局部和全局知识。然而,重叠区域预测需要来自两个输入点云X和Y的额外几何信息。我们可以以简单而高效的方式实现这一点
采用RANSAC来寻找重叠点,遵循的思想就是,我们在这个方法中把非重叠点当成离群点。
我们的掩码预测可以用此公式表示
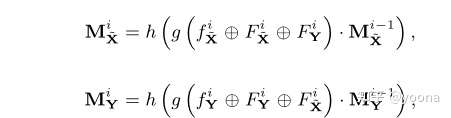
h表示重叠预测网络,它由几个卷积层和一个Softmax层组成
掩码预测的损失函数
我们可以现在就去看看掩码预测的损失函数长什么样子
掩模预测损失的目标是分割输入点云X和Y中的重叠区域。为了平衡正样本和负样本的贡献,在每次迭代处使用 frequency weighted softmax-cross-entropy loss
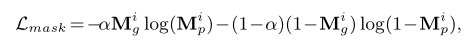
其中, Mp 表示点属于重叠区域的概率, α 表示输入的重叠率。我们定义了假设的掩码标签 Mg 来表示两个输入的重叠区域,该区域是通过设置固定阈值(设置为0.1)来计算的,该阈值是针对通过ground-truth变换变换的源和参考之间的最近点距离而设置的。每个元素都是
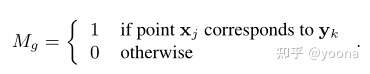
当前掩码是基于前一个掩码估计的,因此每次迭代都需要重新计算标签
损失函数是一个带有权重的交叉熵损失函数,并且权重和此类出现的频率相同(我也不知道为什么,按理来说不应该是少类的权重比较大嘛,有没有大佬可以解释一下)
刚性变换预测
在每次迭代i处给定x和y的逐点特征,我们将它们与从重叠掩模预测模块的中间层输出的特征级联。因此,用于回归变换的特征可以通过掩码预测分支中的分类信息来增强。同时,用于预测模板的特征得益于变换分支中的几何知识。然后,串联的特征被馈送到刚性变换回归网络,该网络产生7D向量,我们使用7D向量的前3个值来表示平移向量t∈R3,并且后4个值以四元数的形式表示3D旋转
文章在提及之前的方法的时候有提到过他们不能充分的利用点云的几何知识,现在看来,是把预测掩码中的特征向量拿到刚性变换的预测中来利用几何知识。
刚性变换的表示公式是:
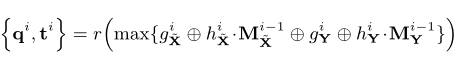
其中 hxi,hyi 表示掩码预测模块中串联的特征向量。
刚性变换损失函数
用四元数{q,t}的方式表示损失函数
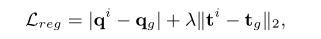
其中下标g的是ground-truth
我们注意到,在训练和推理过程中,使用ℓ1和ℓ2距离的组合可以略微提高性能。在文章的大多数实验中,λ被经验地设置为4.0。
总的损失函数是
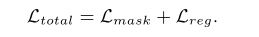
实验
数据集
实验的数据集有:
1)Standford 3D Scan 使用该数据集来测试模型的泛化能力
2)7Scenes 该数据集是在室内环境采集的
3)ModelNet40 这个是需要讲一讲的数据集,也是这篇论文其中一个贡献产生的地方
ModelNet40包含来自40个类别的CAD模型。以前的工作使用的是来自PointNet[21]的经过处理的数据,该方法用于配准任务有两个问题:(1)对于每个对象,它只包含从CAD模型采样的2,048个点。然而,在现实场景中,X中的点在Y中没有精确的对应。对该数据的训练会导致过拟合问题,甚至增加噪声或重采样。(2)它涉及一些轴对称类别,包括瓶、碗、锥、杯、花盆、灯、帐篷和花瓶,图4显示了一些例子。然而,为轴对称数据提供固定的地面真实是不合逻辑的,因为可以获得对称轴上的任意角度以进行准确配准。将标签固定在对称轴上没有任何意义
个人的理解是:给具有对称轴的数据建立ground-truth是不合理的,因为对称轴数据是可以旋转的,在对称轴上旋转任意角度的结果都可以说是一个良好的配准。而仅仅将标签固定在对称轴上,即只配准对称轴也是显然不合理的。
不同于以往的数据采集方式
在本文中,我们提出了一种合适的数据生成方式。具体地说,我们用不同的随机种子从每个CAD模型中均匀采样2048个点40次,然后随机选择其中的2个作为X和Y。它保证我们可以获得每个对象的C240=780个组合。我们将从CAD模型中只采样一次的数据表示为一次采样(OS)数据,并将我们的数据称为两次采样(TS)数据。此外,我们简单地去掉了轴对称范畴。
 这里列举了一些轴对称数据
这里列举了一些轴对称数据
评价指标
我们测量各向异性误差:旋转和平移的均方根误差(RMSE)和平均绝对误差(MAE),以及各向同性误差:
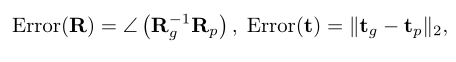
Rg 和 Rp 分别表示由四元数 qg 和 qp 转换的ground-truth旋转矩阵和预测旋转矩阵.
如果刚性对齐是完美的,则所有指标都应为零。角度度量以度为单位
在ModelNet40上的结果
该方法在1)训练数据与测试数据类别相同且无噪声,2)训练数据与测试数据类别不同且无噪声,3)训练数据与测试数据类别相同且增加了高斯噪声。上的表现均优于以前的做法。数据如图:
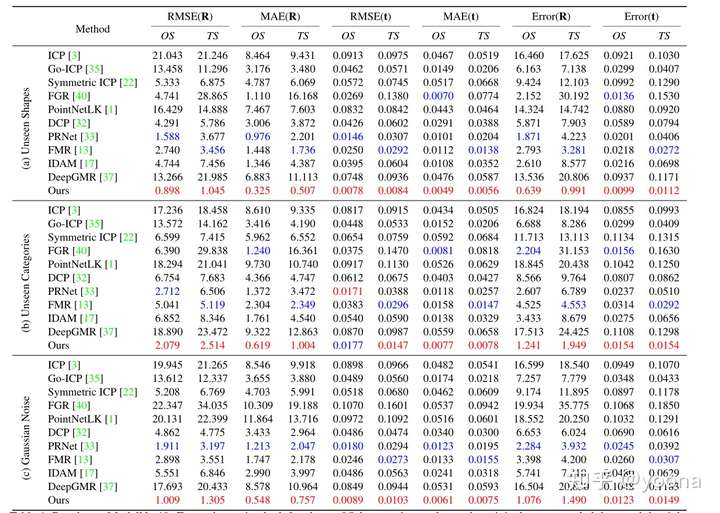 直接看三个类的Error(R)和Error(t)
直接看三个类的Error(R)和Error(t)
可视化的数据更加直观
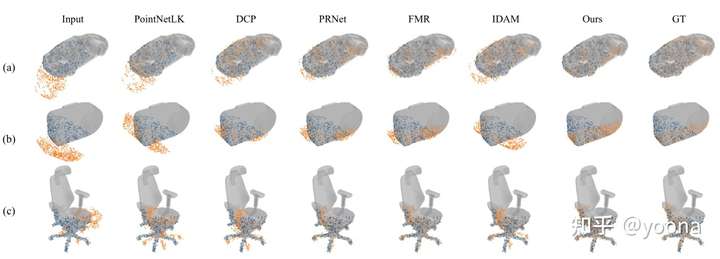 分别是三个类别的结果
分别是三个类别的结果
该方法在具有高斯噪声的训练数据与测试数据类别不同的情况下依旧表现良好
在真实数据上的表现

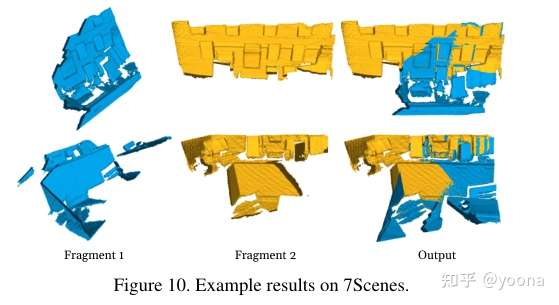
Discussion
重叠掩码的效果
下图展示了重叠掩码的作用:
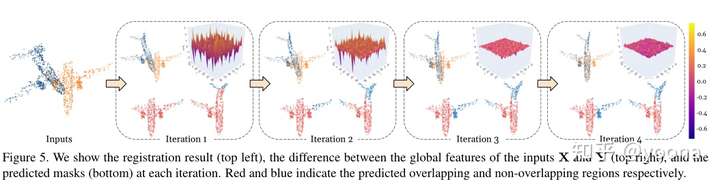
在最初的几次迭代中,全局特征差异很大,并且在给定不准确的重叠遮罩的情况下,输入对齐不佳。在连续迭代的情况下,全局特征差异变得非常小,而对齐和预测重叠掩码几乎是完美的。
鲁棒性证明
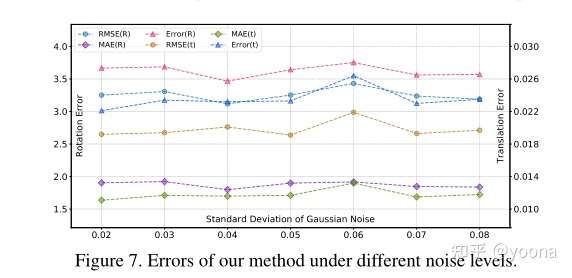
上图给出了在不同噪声下模型的性能,可以看出模型在不同程度的噪声表现出了相当的性能。
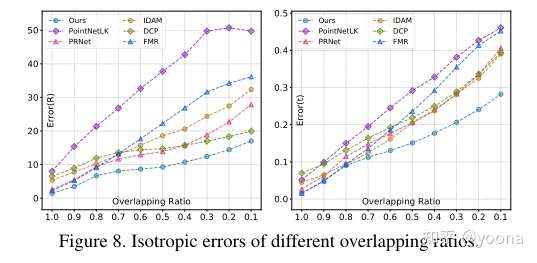
不同的重叠率
如图,该论文的方法在重叠率递减的情况下依旧展示了最好的性能
贡献
- 提出了一种基于全局特征的配准网络OMNet,该网络通过学习掩码来剔除非重叠区域,对噪声和不同的局部方式具有较强的鲁棒性。掩码预测和变换估计可以在迭代过程中相互加强
- 揭示了在采用ModelNet40数据集进行配准时存在的过拟合问题和数据集中不合理的轴对称类别,提出了一种更适合配准任务的数据对生成方法
- 在干净、有噪声和不同局部数据集下与其他工作进行了定性和定量比较,显示了最先进的性能。
声明:本文仅仅作为我在学习道路上的一个记录,一些理解可能不准确,还恳请各位大佬指正。如果有侵犯到任何人的权益,请联系我,我会删除此文。
参考资料
全文:Xu H, Liu S, Wang G, et al. Omnet: Learning overlapping mask for partial-to-partial point cloud registration[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 3132-3141.
【1】Azuma R T. A survey of augmented reality[J]. Presence: teleoperators & virtual environments, 1997, 6(4): 355-385.
【2】Newcombe R A, Izadi S, Hilliges O, et al. Kinectfusion: Real-time dense surface mapping and tracking[C]//2011 10th IEEE international symposium on mixed and augmented reality. Ieee, 2011: 127-136.
【3】Yurtsever E, Lambert J, Carballo A, et al. A survey of autonomous driving: Common practices and emerging technologies[J]. IEEE access, 2020, 8: 58443-58469.